Frage
Was bewirken Algorithmen?
Leben,
Algorithmus
Die Laufzeitkomplexität von Algorithmus A liegt in O(n2 ), die von Algorithmus B in O(n log n). Welcher ist schneller ?
Wann würde man Quicksort oder Mergesort in der Praxis einsetzen?
Es kann sein, dass ich nicht alles angegeben habe, aber dafür gibt es den Bereich "Anderes".
Danke Euch.
Bitte keine sätze
einfach nur kurz und einfach Pro & Contra aufzählen
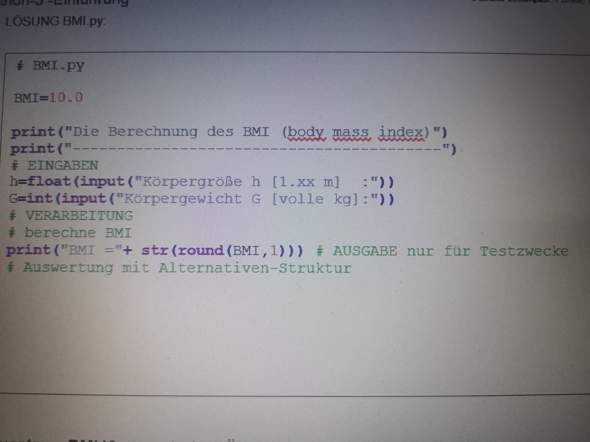
Könnte mir jemand erklären warum bei "Deklaration und Zuweisung" summe=0 steht? Also was bedeutet das genau und was bringt es

Lösch der immer automatisch Kommentare ,die nicht dem Mainstream entsprächen?
Bin gerade dabei die Friedrich Methode zu lernen. Meine Bestzeit ist 2:52 min und ich möchte sie unbedingt verbessern. Jetzt habe ich die f2l Methode gelernt brauche aber dafür um die 1,5 minuten. Jetzt will ich oll anfangen allerdings gibt es dafür gefühlt unendlich Algorithmen. Muss ich die alle auswendig lernen? Und wie kann ich meine Zeiten verbessern?
Lg
Ich kann den alg für diesen 5x5 zauberwürfel parity nicht finden weiß jemand weiter?

Hallo Leute! Ich möchte meine Reichweite aufbessern und habe gesehen, dass es Bots gibt, die beispielsweise Kommentare schreiben. Gibt es gratis Bots und kann man dafür gebannt werden?
MfG Lass228
zahl = 123
quersumme = 0
while len(str(zahl)) >= 1:
str_zahl = str(zahl)
quersumme = int(str_zahl[0]) + int(str_zahl[1])
????
Warum schreiben manche Leute in den Kommentaren bei Youtube manchmal: „Für den Algorithmus.“ Was bringt das?
Und welche Ansatzpunkte hat man, um eventuell die Antwort zu bekommen?
x -4y -2z = -2
2x- 3y +4z = 2
x - 6y -8z = -3
Wie kann ich die Hash von meinem Instagram passwort herrausfinden
Bei mir kommt es oft vor, dass der letzte Stein falsch herum gedreht ist. Wie löse ich diese Situation?

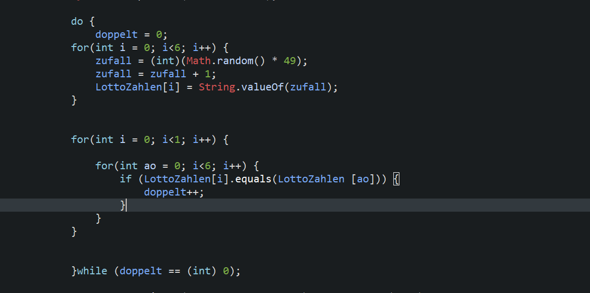
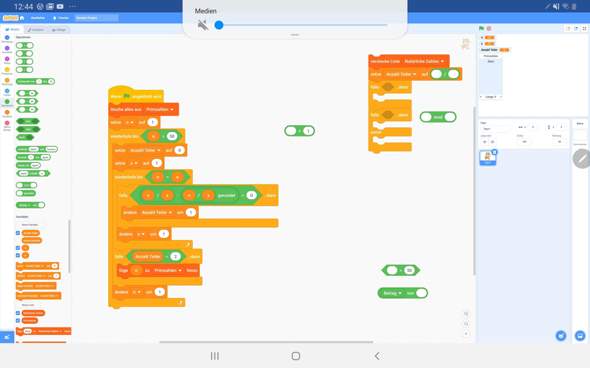
Hi ich hab ein Algorithmus auf Scratch zum finden von Primzahlen bis 50 versucht zu machen. Irgendwie funktioniert es aber noch nicht. Wisst ihr vlt woran das liegt?
Danke im Voraus
Wiederhole solange !t.isEmpty()
Wieso das Ausrufezeichen davor? Was bedeutet es in der Informatik/Algorithmen oder beim Programmieren (beim Pseudocode)

Also ich habe gefunden; Ampel, Navigationsgerät, Suchmaschine....
2n + log n ∈ O (n.logn)
wie kann ich die Aussage beweisen?
danke
Gibt es einen Algorithmus für diesen Fall? Ich bin erst neu beim 4x4. Ich hab versucht ihn so zu lösen, wie einen 3x3. Mit oll hat alles geklappt, nur nicht mit pll.
Bild im Anhang
Gruß